The great thing about a database is that you can ask it a question that you hadn't thought of before and get an answer.
— Michael Stonebraker
From question to data
In this chapter, we want to take a brief look at how datasets and databases are created.
You should remember the following from this chapter:
- data modeling as a step in the analysis of IT applications;
- a step-by-step approach to database development;
- conceptual, logical and physical data model.
Start with a question
In the introductory chapter SQL we have already briefly explained how, using SQL, we can query an existing dataset. In the following chapters we will go into more detail about the possibilities that SQL has to offer. In parallel, we want to explain a different challenge, namely building datasets and databases. We will address the following questions:
- how are datasets and databases created?
- what process leads to a well-built database?
- what determines whether a database is well-built?
Before looking at how datasets and databases are created, we will look at a similar process, namely building a house. Suppose you would like to have a house built, how do you proceed? Most of the time, you start with a question or need to build something. Let's assume that you want to build a house for your family. As soon as you know you are going to build a house, you contact an architect. The architect will start thinking with you about what exactly needs to be built, by asking a lot of questions to fully understand what your house should look like.
Meanwhile, the architect, using his technical expertise, is also going to ensure that while designing your house, a number of basic principles and good practices are respected. As a result of your consultation, the architect draws a first floor plan.
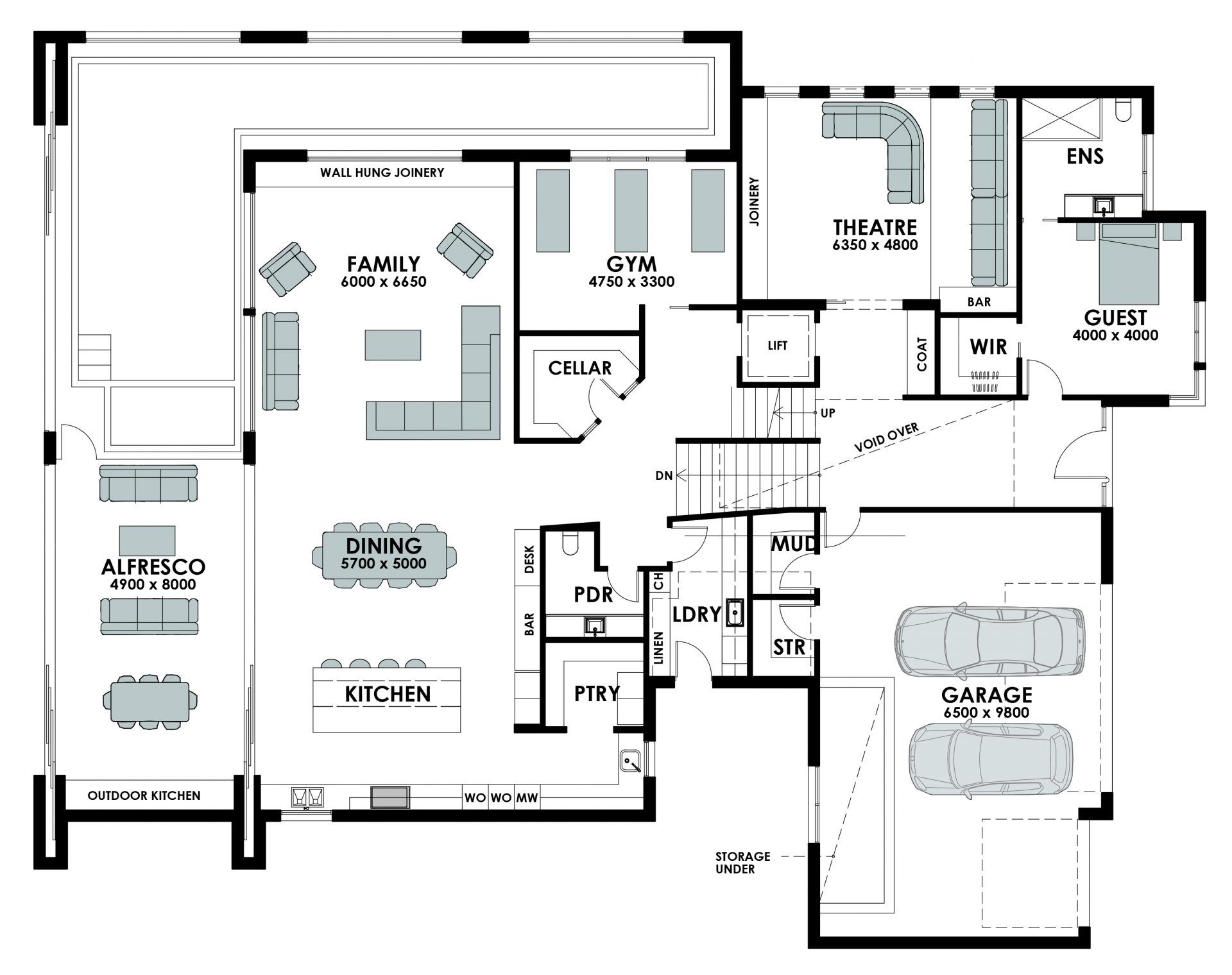
This floor plan is discussed with you to ensure that the architect's interpretation matches your expectations. In later phases, the architect will make more detailed versions of this plan so that contractors, electricians, plumbers, ... know how your house should be made. This detailed floor plan is well kept in order to have an overview of where certain construction elements (water pipes, electricity, support beams, ...) are located.
Request for data
For building a database, the process is similar. A database typically starts with a request to keep track of data, for example, data collected within software. An architect (we have those in IT, too) or an analyst will work with users and developers to consider what data should go into a database. Based on those conversations and their technical expertise, the analyst will draw up a data model that is discussed with the relevant parties.
This model is then further detailed in a number of steps into a building plan for a database. This building plan allows the developers of the database to build the database. It also allows the developers of the software to start developing their application. Because once the structure of the database is agreed upon, the software developer can write code that will work with this structure, without the database already being built. Later when the database is built, the code can be tested. Finally, the models are an important source for documentation for analysts and developers for further development and maintenance of the systems.
Analysis
The development of an IT solution (ideally) follows a roadmap. There are a lot of different standardized variants of such a roadmap, which we will call development methodologies later in the program. A development methodology can be linear or iterative, and consists of a number of stages.
An important phase that occurs in just about every development methodology for IT applications is the analysis phase or analysis for short. Within the analysis phase, we are going to translate the need for an IT application to a number of functional and technical requirements. The result of this phase is called the (requirement-)analysis.
Analysis is an essential phase in which we really try to properly understand the need, the process to be automated, the underlying logic, ... before starting the implementation. In this phase, we will go through documentation, conduct interviews, organize workshops, ... to gather information ourselves. Then we are going to structure that information in a certain way. There are many different methods used within analysis, some of which you will discover in this course and in the further program.
The sub-process of the analysis in which we identify the requirements for information and consequently data mapping, is called data modeling. As a component for the need for software, we are going to evaluate what data needs to be tracked persistently.
In later courses you will learn more about the concept of development methodology and explore different variants (including agile, DevOps, waterfall, rapid application development) in-depth.
Data modeling
Data modeling proceeds in a number of steps. In each step, we try to answer a particular question (the specific questions are discussed below). The result of each step results in a data model, in which we may or may not build on a data model from a previous step. Each step results in a data model and associated documentation.
A data model is a visual and schematic representation of the data that we want to include in a database. It contains the various pieces of data that make up the database and the relationships that exist between these pieces. To draw out the data model, we use a standardized notation.
There are certain advantages of using a standardized notation. First, it promotes the readability of the data model. If there are clear agreements about which symbols are used and how to interpret them, anyone familiar with the notation can read the data model and interpret the data model. Data models can therefore easily be exchanged.
A second advantage is that the notation was developed to present complex concepts in a simple way. It simplifies and speeds up the design of a data model. Add to this the fact that there are a lot of tools that allow you to digitally create them, meaning that you can proceed quickly and efficiently.
Since data modeling of a database is done in steps, and each step results in a data model, we will have multiple data models. We call these layers where each data model forms a particular layer and, as mentioned earlier, answers a particular question.
In our process we distinguish three types (layers) of data models: conceptual, logical and physical.

Conceptual data model
The first step is to draw out a conceptual data model in which we formulate an answer to the question "What information is relevant to the intended IT application?". In this data model, we create a picture of the reality of the users without including technical details or taking technical limitations into account. Instead, the focus is on the relevant concepts and business logic.
The conceptual data model also allows the scope of the data model to be well delineated, so that all involved have a clear view of what is of interest. It provides a view on what is included in the application, and what is not included.
In drawing the conceptual model, we try to answer the following questions:
- what concepts are important to our application?
- how are we going to describe those concepts?
- what connections are there between these concepts?
The conceptual data model typically emerges as a collaboration between analysts and users. During workshops, interviews, etc., the users describe what information is relevant.
The analyst collects this information and compiles it into a conceptual data model. This data model serves as a means of communication between the various parties involved. The simple nature of the conceptual data model allows users to easily evaluate whether the analysts' interpretation is correct. On the other hand, it contains enough information for the analysts to continue their work.
Very important: at this level, there is still no talk about technology, just high-level what information is relevant to the users. This is also what makes the conceptual data model so valuable: after this step, the development team of the application can still take any technical direction.
The conceptual data model shown below tells the following story: “A student (with some data such as r-number as ID etc.) takes at least one course, while this course (code, number of Study Points SP etc.) can be taken by multiple students. It is also possible that there is a course that is not chosen by any student.”. This drawing can also be read by non-technical people and can thus serve as a basis for a conversation.

We will go into more detail later about the conceptual data model and how it is established.
Logical data model
Once we have a view of the information and consequently the concrete data, facts or data relevant to the users, we try to answer the following question: "Which database model is best suited for the development of our database?". In fact, there are several database models (not to be confused with data models) where each of the database models defines a specific way to structure data. Each database model has its advantages and disadvantages and thus its specific applications, so proper consideration is necessary.
The choice of a particular database model is typically made in consultation between the analysts (with visibility into the data being modeled), the architect (with visibility into the broad technical environment in which the application will be developed) and the developers (with visibility into the technology that will be used for the application). The impact of the choice is not only relevant to the database, but it also imposes constraints on the DBMS and technology that can be used.
After choosing a particular database model the analyst translates the conceptual model to a logical model taking into account the specific rules of the database model. Some database models, for example, are going to place a constraint on the type of relationships that can exist between the data. In this case, during the conversion we are going to convert the unsupported types of relationships to relationship types that are supported. No doubt this all sounds a bit abstract, but we will come back to this in detail later.
In quite a few cases, a relational database model will be chosen. Therefore, in the case of this choice, the logical data model is called a relational data model. We focus within this course on the relational database model and will come back to this in great detail in a later chapter.
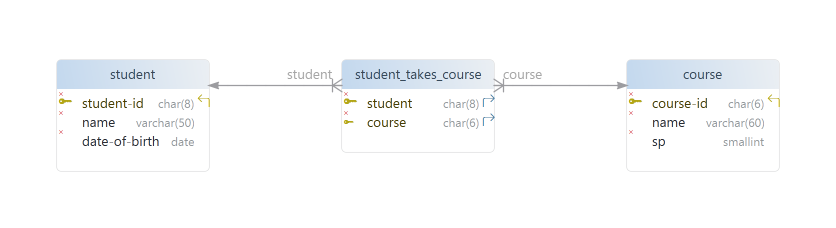
In the following figure you will find the translation of the conceptual model into a logical model. A relational data model was chosen. It is already a lot more technical (three tables, primary and foreign key, ... see later), but still leaves out certain details because the specific DBMS to be used is not yet chosen.

Forms are also defined for relational data models; we call these normal forms. There are different levels of normal forms. Each normal form consists of a number of technical criteria. Each level imposes additional criteria. A data model that meets the criteria of a normal form satisfies the normal form. The criteria are defined to prevent possible errors in the use of the database. Thus, by indicating that a data model follows a certain normal form, you provide a guarantee that certain rules within the data model are respected. We will come back to this later.
The logical data model is just because of its conversion to a specific database model already a bit more technical than the conceptual data model. This also makes the readability of the data model more difficult for non-IT contributors. Nevertheless, the data model still contains too little technical information for the developers of the database, so that an additional step is needed, namely the conversion for a specific DBMS. So on to the physical data model ...
A full chapter is also devoted to the logic model.
Physical data model
The final step focuses on the question “Which DBMS are we going to use to store the data?”. In the development of the physical data model, decisions are made about how the data will be physically structured within the database, taking into account the chosen DBMS. Each DBMS has its own set of capabilities and challenges that a development team can take advantage of or must take into account. In addition, there are also many considerations about performance, security, ... that must be made. All of these technical decisions come together in the physical data model.
In this phase, architects, database administrators and developers will evaluate which DBMS will be used. In a lot of cases, this choice is already fixed since most organizations have already made a choice in their architecture. Combining different DBMS in the same organization means additional complexity and cost, so that is avoided whenever possible.
Once a DBMS is chosen, database administrators and developers will evaluate the structure of the database and technical details will determine how the data will be stored. This analysis results in the physical data model that contains all this information. The physical data model allows the developers to implement the necessary structures and build the database.
The last figure translates the previous (logical) relational data model
into a physical data model specific to PostgreSQL. The drawing now
includes many concrete details, such as data types (char(8), smallint, ...). By the way, it was created with another
tool (DBSchema, see later).
We will return to the physical data model in a later chapter.