Why did the database administrator leave his wife?
She had one-to-many relationships.
—onbekende auteur
Eén-op-veel relaties
In het volgende hoofdstuk introduceren we SQL-query’s die meerdere
tabellen gebruiken: JOINS. Je hebt dan natuurlijk een schema
nodig dat uit meerdere tabellen bestaat. Dit hoofdstuk laat je kennismaken
met een één-op-veel relatie tussen twee tabellen. In één van de
volgende lessen over modelleren
wordt dit volledig uitgewerkt. Hier vind je enkel een korte inleiding.
Twee tabellen
In de vorige hoofdstukken werden de verschillende componenten van een SELECT statement uitgewerkt. Als basis gebruikten we een tabel die de vertaling
was van dit conceptueel model:

Aparte tabellen
Dit schema heeft één entiteittype (‘Opleidingsonderdeel’) met een aantal attributen. Eén van die attributen is de lectorcode van de coördinator van het OPO. Elk OPO heeft immers een unieke coördinator. Het ligt voor de hand om een tweede entiteittype ‘Lector’ toe te voegen aan het schema. We hebben immers heel wat informatie over lectoren. Dit entiteittype bevat informatie over alle lectoren, niet alleen de coördinatoren van een OPO. Een naïeve poging is volgende figuur:

Als je dit vertaalt naar PostgreSQL krijg je twee aparte tabellen. Deze structuur is echter een bron van problemen. We vermelden twee mogelijke fouten:
- Iemand voegt een rij (= een nieuw opleidingsonderdeel) toe aan de tabel ‘Opleidingsonderdeel’ met een coördinator die niet in de tabel ‘Lector’ zit.
- Iemand verwijdert een rij in de tabel ‘Lector’. De lector uit deze rij is echter ook coördinator van een OPO.
Beide bewerkingen zorgen ervoor dat de databank fouten zal bevatten. Je kan dan van sommige OPO’s geen info meer opzoeken over de coördinator van het OPO. Dat is niet toelaatbaar. Je wilt dat je RDBMS (‘Relationeel DataBase Management Systeem’) je beschermt tegen operaties die fouten introduceren in het schema.
Gekoppelde tabellen
Het probleem is natuurlijk dat de twee tabellen niet zomaar los van elkaar mogen bestaan. Er is een relatie tussen beide. Het conceptueel model uit volgende figuur maakt deze relatie zichtbaar:

Van rechts naar links lees je de relatie als ‘is coördinator van’, van links naar rechts zou het dan iets kunnen worden in de stijl van ‘heeft als coördinator’. Elke OPO heeft minstens één en maximum één (dus juist één) coördinator. Niet elke lector is coördinator van een OPO, maar een lector kan mogelijk wel van meerdere OPO’s coördinator zijn. De kardinaliteit aan de kant van Lector is dus (0, N). Dit is dus een voorbeeld van een één-op-veel relatie.
Merk op dat het attribuut ‘Coordinator’ uit een eerdere figuur is weggevallen. Het is immers vervangen door een relatie met een nieuw entiteittype ‘Lector’ omdat we de behoefte voelen om meer dan alleen maar een nummer bij te houden van een lector.
Vertaling naar relationeel model
Hoe vertaal je nu deze één-op-veel relatie naar een relationeel model? PostgreSQL is immers een voorbeeld van een relationele databank. Als we het conceptueel model uit de vorige sectie willen vertalen naar een logisch model, zal dat logisch model een relationeel model moeten zijn.
Over logische modellen hoor je alles in detail in het hoofdstuk ‘Logisch datamodel’. Dit deel heeft enkel als doel om je hiermee kort te laten kennismaken
zodat we het volgend deeltje in onze verkenning van de taal SQL (nl.
JOIN) kunnen uitwerken. Het logisch model ziet er als volgt
uit:

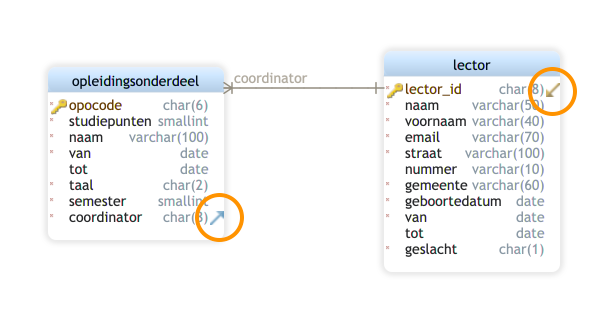
Voorlopig volstaat het dat je dit diagram kan lezen en dat is niet eens zo moeilijk:
- Elk entiteittype wordt een tabel, voorgesteld door een rechthoek met een titel: Opleidingsonderdeel en Lector.
- Elk attribuut van een entiteittype wordt een kolom in de tabel.
- Elke tabel heeft een ‘primary key’ (PK), hier voorgesteld in het geel. Die primaire sleutel heeft een unieke waarde voor elke rij in de tabel.
- Elk opleidingsonderdeel heeft verplicht één coördinator. Er is dus een relatie tussen beide tabellen. In de tabel ‘Opleidingsonderdeel’ is een kolom ‘Coordinator’ toegevoegd. Deze kolom is een zogenaamde ‘Foreign Key’ (FK, ‘vreemde sleutel’, aangeduid in het groen) omdat elke waarde van deze kolom moet voorkomen als PK van de Lector-tabel.
- De verbinding tussen beide tabellen maakt duidelijk dat de inhoud van de kolom overeenkomt met de waarde van de kolom ‘Lector_id’. Het symbool (twee streepjes) in de kleine blauwe cirkel geeft aan dat elk opleidingsonderdeel verplicht één lector als coördinator heeft.
- Omgekeerd betekent het symbool in de grotere oranje cirkel dat elke lector coördinator kan zijn van nul (bolletje) of één of meerdere OPO's (kraaienpoot).
Dit logisch model wordt tenslotte geconverteerd naar een fysiek model, waarbij we nog meer informatie specifiëren die afhangt van de specifieke eigenschappen van het gekozen RDBMS (in ons geval PostgreSQL). Een voorbeeld is bijvoorbeeld de datatypes van de kolommen.
Het fysiek model werd getekend met DBSchema. Ook daarop komen we later
uitgebreid terug. Dit fysiek model komt overeen met het logisch model, in een
iets andere notatie (bemerk de blauwe vertrekkende pijl die aangeeft dat dit veld een FK is die verwijst naar de
geelbruine aankomende pijl
bij lector_id). Ook heeft elk veld een datatype gekregen (char, date, …):
Deze één-op-veel relatie toevoegen in de databank gaat als volgt:
- Maak eerst de tabel ‘lector’.
-
Zoek naar de primaire sleutel (‘primary key’) van de lectortabel. Deze
primaire sleutel is het veld ‘lector_id’. Het datatype van deze primaire
sleutel is een
char(8), want een lectorcode begint altijd met een ‘u’ gevolgd door zeven cijfers. Merk op dat we eigenlijk de benamingen ‘veld’ en ‘kolom’ door elkaar gebruiken. -
In de tabel ‘opleidingsonderdeel’ moet er nu een kolom gemaakt worden
met exact hetzelfde datatype als het datatype van de primaire sleutel in
de lectortabel, dus ook een
char(8). We noemen dit ‘de primaire sleutel overbrengen’ en spreken in de OPOtabel over een ‘externe sleutel’ (of ‘foreign key’). -
Deze twee kolommen koppel je nu m.b.v. een beperking (
constraint). - Voer nu eerst de data in in tabel ‘lector’.
- Daarna kan je tabel ‘opleidingsonderdeel’ vullen met rijen.
Realisatie in je eigen schema
Vanaf hier moet je zelf de handen uit de mouwen steken en de twee tabellen effectief aanmaken. We willen immers dat je straks in je eigen tabellen informatie kan toevoegen en verwijderen en dat kan niet als we iedereen in dezelfde tabel laten werken. Start dus pgAdmin en voer de volgende stappen ook effectief uit.
Als je onderstaand stappenplan (gebaseerd op de stappen in vorige sectie)
volgt, bekom je twee gekoppelde tabellen, gevuld met data. Hierop volgen
dan enkele kleine oefeningen. In het volgend hoofdstuk over JOIN gebruiken we dan dit schema als basis.
- De volgende stappen gaan ervan uit dat iedereen een eigen schema heeft met als naam ‘rxxxxxxx’, waarbij je natuurlijk je eigen r-nummer gebruikt. Het gemakkelijkst is dat je de pooling connectie gebruikt op 62526.
-
Kijk na of er in je schema eventueel al een tabel
‘opleidingsonderdeel’ of ‘lector’ aanwezig is. Als dat het geval is,
verwijder dan deze tabel met een
DROP TABLE …in een query tool. Remember: ofwel gebruik je voor elke tabelnaam eerst de naam van het schema, gevolgd door een punt en dan de tabelnaam, ofwel zet je jesearch_pathgoed. - Download het bestand ‘lector-opo-SQL.txt’. De volgende stappen gebruiken stukjes uit deze SQL code om alles te bouwen en te vullen met data. Je kan telkens het stukje kopiëren uit dit tekstdocument en dat dan plakken in je query tool en uitvoeren.
-
Maak de tabel ‘lector’ door de
CREATEcode uit te voeren voor deze tabel uit het bestand dat je zonet gedownload hebt. Niets nieuws te zien hier: twee velden zijn niet verplicht, enkele verschillende datatypes, een primaire sleutel, … -
Maak nu de tabel ‘opleidingsonderdeel’ door het juiste stukje te
kopiëren / plakken uit het txt-bestand. Over deze code moeten we een
klein beetje uitleg geven:
CREATE TABLE rxxxxxxx.opleidingsonderdeel ( opocode char(6) NOT NULL , ... coordinator char(8) NOT NULL , CONSTRAINT pk_opleidingsonderdeel_opocode PRIMARY KEY ( opocode ), CONSTRAINT fk_opleidingsonderdeel_lector FOREIGN KEY ( coordinator ) REFERENCES rxxxxxxx.lector( lector_id ) );Deze laatste
CONSTRAINTis nieuw. Vrij vertaald zegt deze beperking het volgende: “de kolom ‘coordinator’ van deze tabel verwijst naar de primaire sleutel ‘lector_id’ van de tabel ‘lector’ en is dus een vreemde sleutel”. Het is een goed idee om elkeCONSTRAINTeen zinvolle naam te geven. In dit geval: ‘fk’ (voor ‘foreign key’) gevolgd door de twee namen van beide betrokken tabellen. De tool DBSchema die we later hiervoor zullen gebruiken, doet deze naamgeving automatisch. -
Denk eens logisch na over de juiste volgorde van het invullen van de data in de twee
tabellen. De OPOtabel hangt af van de lectortabel. Je kan pas een
coördinator aanduiden voor een OPO als die al in de lectortabel
bestaat. Vul dus eerst de lectortabel door een kopie / plak
bewerking van de
INSERTstatements uit het txt-bestand.INSERT INTO rxxxxxxx.lector( lector_id, naam, voornaam, email, straat, nummer, gemeente, geboortedatum, van, tot, geslacht ) VALUES ( 'u0042352', 'Adriaens', 'Gerben', 'gerben.adriaens@ucll.be', 'Ankerstraat', '12', '1330 Rixensart', '1984-02-16', '2017-09-01', null, 'M'); INSERT INTO rxxxxxxx.lector( lector_id, naam, voornaam, email, straat, nummer, gemeente, geboortedatum, van, tot, geslacht ) VALUES ( 'u0057764', 'Bogers', 'Goedele', 'goedele.bogers@ucll.be', 'Elzasgang', null, '2830 Willebroek', '1979-09-09', '2006-11-20', null, 'V'); INSERT INTO ... -
Tot slot, nu de lectortabel gevuld is, kan je de OPOtabel ook met
data vullen. Dit keer doen we het met een CSV lijst. Kopieer deze
regels uit de lijst en zet die in een nieuw .csv bestand. Importeer
dit .csv bestand zoals (zie hoofdstuk ‘CSV-bestand’):
opocode,studiepunten,naam,van,tot,taal,semester,coordinator MBI71A,3,Probleemoplossend denken,2016-09-15,2022-09-14,nl,1,u0012047 MBI65X,4,Webontwikkeling 1,2017-09-15,2022-09-14,nl,1,u0012047 MBI66X,4,Webontwikkeling 2,2017-09-15,2022-09-14,nl,2,u0015529 MBI20X,3,MobieleToepassingen,2018-09-15,2023-09-14,nl,5,u0057764 MBI26A,6,Computersystemen,2013-09-15,2022-09-14,nl,6,u0041234 ... -
Klaar! Voer een
SELECT * FROM ...uit op beide tabellen om de data te bekijken.
Reactie van het RDBMS op fouten
Maak nu volgende kleine oefeningen. Soms is het expliciet de bedoeling om een fout te maken zodat je leert de foutmeldingen van ons RDBMS goed te interpreteren.
Voeg een nieuwe lector toe. Het gaat om Anouk De Ridder met u-nummer
u0012047. Ze woont in de Kerkstraat 23 in 3053 Haasrode, is geboren op 5
mei 1994 en komt vandaag in dienst. Mailadressen aan UCLL zijn
eenvoudig: voornaam.familienaam@ucll.be, dus dat kan je zelf
samenstellen. Verklaar wat er gebeurt als je een INSERT met
bovenstaande gegevens uitvoert.
Je krijgt een foutmelding dat er al een lector met deze lectorcode
bestaat. Aangezien de lectorcode de primaire sleutel is (en die
dus
uniek moet zijn) geeft het RDBMS een foutmelding en wordt de INSERT niet uitgevoerd. Ook hier merk je dat het nuttig is om je CONSTRAINT een zinvolle naam te geven: er is iets mis met primary key ‘lector_id’
in de tabel ‘lector’:
ERROR: duplicate key value violates unique constraint "pk_lector_lector_id"
DETAIL: Key (lector_id)="(u0012047)" already exists.
SQL state: 23505Stomme typfout natuurlijk hierboven. Het u-nummer van Anouk is niet u0012047 maar wel u0099999. Voeg deze lector nu toe aan de tabel ‘lector’.
Dit keer geen probleem als je iets in deze stijl hebt uitgevoerd:
INSERT INTO rxxxxxxx.lector( lector_id, naam, voornaam, email, straat, nummer,
gemeente, geboortedatum, van, tot, geslacht ) VALUES ( 'u0099999', 'De Ridder',
'Anouk', 'anouk.deridder@ucll.be', 'Kerkstraat', '23', '3053 Haasrode',
'1994-07-05', '2022-10-15', null, 'V');De server antwoordt dat er met succes één rij is toegevoegd:
INSERT 0 1
Query returned successfully in 85 msec.Nog dezelfde dag dat ze is toegevoegd aan de databank, beslist Anouk De Ridder dat ze toch geen lector wilt worden. Verwijder haar uit de tabel ‘lector’.
DELETE
FROM rxxxxxxx.lector
WHERE lector_id = 'u0099999'Je kan natuurlijk ook volgende code gebruiken, maar dan verwijder je wel iedereen met deze naam. Wie weet is er aan UCLL nog wel iemand met de naam ‘Anouk De Ridder’ en dan wordt deze persoon ook uit de tabel verwijderd:
DELETE
FROM rxxxxxxx.lector
WHERE naam = 'De Ridder' AND voornaam = 'Anouk'. -- gevaarlijk!De server antwoordt dat er één rij succesvol verwijderd is:
DELETE 1
Query returned successfully in 53 msecVerwijder Bram De Smet uit Leuven uit de lectortabel. Verklaar wat er gebeurt.
Met deze code verwijder je de rij:
DELETE
FROM rxxxxxxx.lector
WHERE voornaam = 'Bram' AND naam = 'De Smet' AND gemeente LIKE '%Leuven'De server geeft echter deze foutmelding:
ERROR: update or delete on table "lector" violates foreign key constraint
"fk_opleidingsonderdeel_lector" on table "opleidingsonderdeel"
DETAIL: Key (lector_id)=(u0012047) is still referenced from table "opleidingsonderdeel".
SQL state: 23503Je leest deze foutmelding als volgt: “De tabel ‘opleidingsonderdeel’ bevat minstens één rij die verwijst naar deze lector. Deze lector is dus coördinator van een OPO. Daarom mag die dus niet verwijderd worden.”. In het geval van Anouk De Ridder was er geen probleem, want haar u-nummer komt nergens in de OPOtabel voor en dus mag zij veilig verwijderd worden uit die tabel.
Voeg tenslotte een nieuw OPO toe: ‘Bomen en grafen’ met code ‘MBI39A’.
Dit OPO werd gegeven in het tweede semester, is dit jaar gestopt en liep
van 15 september 2017 tot en met 14 september 2022. Het OPO werd in het
Nederlands gegeven en had 3 studiepunten. Coördinator van het OPO was de
lector met u-nummer ‘u0099998’. Schrijf de INSERT, voer uit
en interpreteer het resultaat.
Met deze code doe je de INSERT:
INSERT INTO rxxxxxxx.opleidingsonderdeel( opocode, studiepunten, naam, van,
tot, taal, semester, coordinator ) VALUES ( 'MBI39A', 3, 'Bomen en grafen',
'2017-09-15', '2022-09-14', 'nl', 2, 'u0099998');
De databankserver weigert om deze INSERT uit te voeren en
geeft volgende foutmelding:
ERROR: insert or update on table "opleidingsonderdeel" violates
foreign key constraint "fk_opleidingsonderdeel_lector"
DETAIL: Key (coordinator)=(u0099998) is not present in table "lector".
SQL state: 23503Aangezien er nog geen lector met deze lectorcode aanwezig is in de lectortabel, kan je geen nieuw OPO toevoegen met als coördinator deze lector. Pas als je deze lector hebt toegevoegd in de tabel ‘lector’, kan je het OPO toevoegen.