Confusion is part of programming.
—Felienne Hermans, The Programmer's Brain
De GROUP BY en HAVING clauses in detail
Rijen groeperen
In het hoofdstuk over het importeren van een CSV-bestand kwam je een eerste keer in contact met het groeperen van rijen. Vaak gaat het over een vraag waarin het woord ‘per’ een rol speelt. “Geef per lector het aantal OPO’s waarvoor deze lector coördinator is”. “Geef het totaal aantal studiepunten van alle OPO’s die nu of vroeger in die taal gegeven zijn”. Toegegeven, die laatste zin bevat het woordje ‘per’ niet, maar je kan ze ook herformuleren als “Geef per taal het totaal aantal studiepunten van alle OPO's die in die taal gegeven worden of zijn.”
Het beeld dat we gebruiken is: groepeer de rijen op eenzelfde waarde van een bepaald veld (of velden) in een doosje. Van dat doosje kan je dan geen individuele rijen meer bekijken. Je moet je dan beperken tot samenvattende informatie.
Laten we als voorbeeld bovenstaande vraag behandelen: “Geef per lector het aantal OPO’s waarvoor deze lector coördinator is of was”.
Je kan de query's nog steeds uitvoeren op de tabel ‘opleidingsonderdeel’ in het schema ‘uclloket’ van de databank ‘df’ of in je eigen versie hiervan.
In een eerste stap schrijf je als oefening de query die onderstaande figuur genereert, nl. een lijst van alle coördinatoren met opocode, naam van het opo en semester, geordend volgens stijgende lectorcode (u-nummer):

Niet zo'n moeilijke query, toch?
SELECT coordinator, opocode, naam, semester
FROM opleidingsonderdeel
ORDER BY coordinatorJe leest in deze figuur dat lector ‘u0012047’ coördinator is (of was) van ‘Probleemoplossend denken’, ‘Webontwikkeling 1’ en ‘Front-end Development’. Als je nu groepeert per lector dan gaan alle rijen met dezelfde waarde voor de kolom ‘coordinator’ samen in één doosje. Het eerste doosje bevat zo drie rijen. Op het doosje staat de naam van het veld dat voor al deze rijen gemeenschappelijk is, dus ‘u0012047’.
Het tweede doosje met als label ‘u0015529’ bevat twee rijen. Het derde doosje (‘u0032987’) bevat maar één rij, enz.
Doordat deze rijen samen in een doosje zitten kan je geen individuele
gegevens in de SELECT clause meer opvragen. Als je dat probeert
krijg je een typische foutmelding, zoals volgend stukje code laat zien:
SELECT coordinator, opocode, naam, semester
FROM opleidingsonderdeel
GROUP BY coordinator
-- het resultaat van deze query is deze foutmelding:
ERROR: column "opleidingsonderdeel.opocode" must appear in the GROUP BY clause
or be used in an aggregate function
LINE 2: select coordinator, opocode, naam, semester
^
SQL state: 42803
Character: 50Deze query toont enkel een overzicht van alle ‘etiketten’ van de doosjes en wordt probleemloos uitgevoerd:
SELECT coordinator
FROM opleidingsonderdeel
GROUP BY coordinator
Je mag enkel in het doosje kijken en bepaalde samenvattende informatie
geven in de SELECT, zoals het aantal rijen, de som van alle
rijen wat een bepaalde kolom betreft. We noemen deze samenvattende functies ‘aggregatiefuncties’ en spreken
over data ‘aggregeren’. In de volgende sectie bekijken we verschillende van deze functies.
Aggregatiefuncties
Aantal rijen tellen
De vraag die we nog steeds trachten te beantwoorden is “Geef per lector het aantal OPO’s waarvoor deze lector coördinator is of was”. In deze zin
weet je ondertussen al dat het stukje ‘per lector’ betekent dat je de rijen
moet groeperen die dezelfde waarde voor coordinator hebben.
Het aantal rijen tellen dat in één doosje zit
doe je m.b.v. de functie COUNT() (documentatie). Als je volledige rijen wilt tellen, gebruik je COUNT(*).
De uiteindelijke query die het antwoord op de vraag oplevert is:
SELECT coordinator, COUNT(*)
FROM opleidingsonderdeel
GROUP BY coordinator
ORDER BY coordinatorSom van bepaalde gegevens in een groep
Een tweede aggregatiefunctie is SUM(). Je telt hiermee waarden in een bepaalde kolom op. Opgepast: we zien geregeld studenten COUNT() en SUM() verwisselen! Maak nu volgende oefening.
Schrijf een SQL query die het overzicht genereert van het totaal aantal studiepunten waarvoor een lector coördinator is. Orden het resultaat volgens dalend totaal aantal studiepunten. Je moet onderstaande figuur bekomen. Zoals altijd: let je ook op de juiste hoofding van elke kolom?
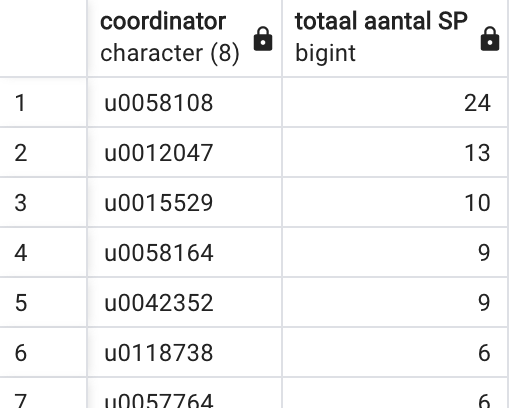
SELECT coordinator, SUM(studiepunten) AS "totaal aantal SP"
FROM opleidingsonderdeel
GROUP BY coordinator
ORDER BY 2 DESCMinimum, maximum en gemiddelde
De laatste drie aggregatiefuncties zijn MIN(), MAX() en AVG(), respectievelijk voor het minimum, maximum of
rekenkundig gemiddelde van waarden in een bepaalde kolom. Maak
volgende oefeningen.
Maak een lijst die voor elk semester het gemiddeld aantal studiepunten toont. Orden de antwoordrijen op semester van klein naar groot. Je moet onderstaande figuur bekomen. Kan je ook de naam van het OPO vermelden?
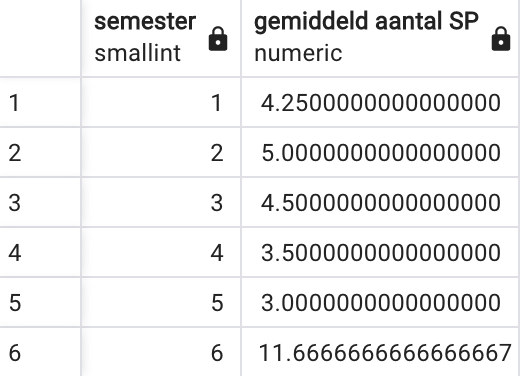
Niet elke opgave zal het woordje ‘per’ bevatten. Taal kent heel wat
alternatieven om toch hetzelfde te vragen. Hier zal je dus moeten
groeperen per semester en moet je de aggregatiefunctie AVG() gebruiken. Vanzelfsprekend kan je geen informatie van individuele OPO's
opvragen (zoals de naam) want dat is ‘informatie die in het doosje zit’.
Volgende query is een mogelijke oplossing:
SELECT semester, AVG(studiepunten) AS "gemiddeld aantal SP"
FROM opleidingsonderdeel
GROUP BY semester
ORDER BY 1Iets moeilijker … Geef een overzicht per taal van het aantal OPO’s van minstens 4 SP dat in die taal onderwezen wordt. Je hoeft niet te ordenen.
SELECT taal, COUNT(*) AS aantal
FROM opleidingsonderdeel
WHERE studiepunten >= 4
GROUP BY taalGroeperen op een expressie
Meestal groepeer je op een bepaalde kolom, maar het is ook mogelijk om te
groeperen op een ‘berekende kolom’ (expressie). Elk OPO heeft een
startdatum. Uit deze startdatum kan je gemakkelijk het jaar halen met EXTRACT . We geven bij wijze van voorbeeld de query die volgende vraag
beantwoordt: “Geef een overzicht voor elk jaar hoeveel OPO’s er nieuw in
de opleiding gekomen zijn in dat jaar”.
SELECT EXTRACT(year FROM van), COUNT(*) AS "aantal OPOs"
FROM opleidingsonderdeel
GROUP BY EXTRACT(year FROM van)
ORDER BY 1Groeperen op meerdere kolommen
De volgende query groepeert op twee kolommen: semester en studiepunten:
SELECT semester, studiepunten, COUNT(*)
FROM opleidingsonderdeel
GROUP BY semester, studiepunten
ORDER BY 1, 2Deze query maakt 15 ‘doosjes’ (zie figuur). Het eerste doosje (oranje rand) toont op het etiket “semester 1, OPO’s met 3 SP”. In dit doosje zitten er vier rijen. Het tweede doosje (blauwe rand) is “semester 1, OPO’s met 4 SP”. Zo is er maar één OPO. enz.
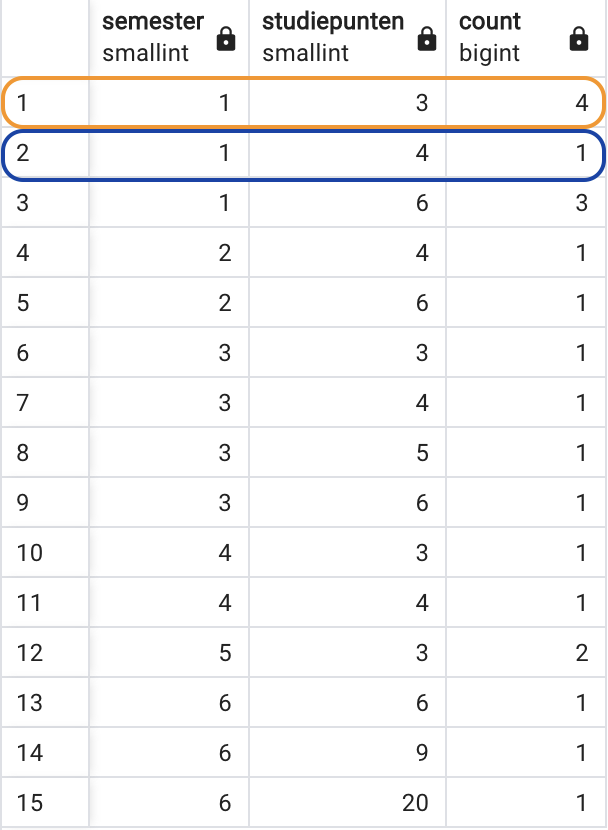
HAVING
De HAVING clause werd al behandeld in het hoofdstuk over CSV-bestanden. Studenten vinden het vaak moeilijk om het onderscheid te maken met de
WHERE clause en dat is begrijpelijk want ze doen iets vergelijkbaars.
De
WHERE selecteert direct na de uitvoering van de FROM component
welke rijen behouden mogen blijven. Daarmee wordt dan verder
gerekend.
De HAVING component echter wordt pas uitgevoerd na het maken van
de ‘doosjes’ bij het groeperen. Deze conditie beslist welke doosjes mogen blijven en welke uit het
resultaat zullen verdwijnen.
Oefeningen
Maak nu volgende oefeningen.
Geef voor oneven semesters een overzicht van het aantal studiepunten en het aantal OPO’s in dat semester. Sorteer volgens dalend aantal studiepunten. Zorg dat je de volgende figuur bekomt.
Een tip om de oneven semester te vinden: bekijk hiervoor de mogelijkheden van de rest bij gehele deling (de zogenaamde ‘modulo’ bewerking), doe een zoekopdracht naar ‘Modulo’ op de pagina https://www.postgresql.org/docs/current/functions-math.html.
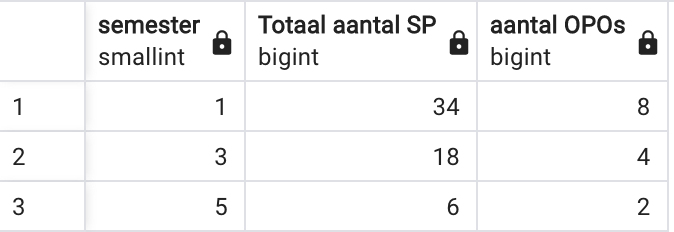
SELECT semester, SUM(studiepunten) AS "Totaal aantal SP", COUNT(*) AS "aantal OPOs"
FROM opleidingsonderdeel
WHERE semester %2 != 0
GROUP BY semester
ORDER BY 2 DESCHoeveel verschillende coordinatoren zijn er per semester?
SELECT SEMESTER, COUNT(DISTINCT(coordinator)) AS AANTAL_VERSCH_COORDINATOREN
FROM opleidingsonderdeel
GROUP BY semesterGeef alle semesters met twee of meer opvolgvakken (vakken die eindigen op ‘2’) per semester.
SELECT semester, COUNT(naam) AS AANTAL_OPVOLG_VAKKEN
FROM opleidingsonderdeel
WHERE naam LIKE '%2'
GROUP BY semester
HAVING COUNT(naam) >= 2;Dit geeft een ‘verkeerd’ resultaat omdat vak “Communicatie in het Frans 2 (sem 2)” de (onuitgesproken?) conventie qua naam niet volgt. Volgende versie geeft mogelijk een beter resultaat:
SELECT semester, COUNT(naam) AS AANTAL_OPVOLG_VAKKEN
FROM opleidingsonderdeel
WHERE naam LIKE '%2' OR naam LIKE '%2 (%'
GROUP BY semester
HAVING COUNT(naam) >= 2;Oefeningen SQLzoo
Maak oefeningenreeks 5 op aggregatiefuncties (tabel ‘world’).