No night of drinking or drugs or sex could ever compare to a long evening of productive hacking.
—Lynn Voedisch
Tabellen combineren met INNER JOIN
In vorige hoofdstukken zijn alle componenten van een SELECT query
de revue gepasseerd, behalve eentje: de FROM component. Er viel
ook niet zo veel over te vertellen, want we hadden toch maar één tabel. In
dit deel gebruiken we meerdere tabellen in een query.
Volgend filmpje legt de principes van het cartesisch product en join goed uit. Bekijk het eerst, volg dan onderstaande tekst en maak de oefeningen die je in de tekst vindt.
Impliciete JOIN
We gebruiken een eenvoudig voorbeeld om het principe uit te leggen. Stel dat je een lijst wilt van de mailadressen van alle OPOcoördinatoren zoals in onderstaande figuur. Na het vorig hoofdstuk zou je in je eigen schema twee gekoppelde tabellen moeten hebben: ‘lector’ en ‘opleidingsonderdeel’.

Werk nu volgend voorbeeld uit door de code van alle stappen uit te proberen in je eigen schema. Vergeet niet de naam van je schema te specifiëren bij elke tabel, ofwel je search_path goed te zetten. In de codevoorbeelden hieronder kozen we voor deze laatste oplossing.
Cartesisch product van meerdere tabellen
De lectortabel bevat 18 rijen, wat je eenvoudig met een COUNT(*) kan controleren:
SELECT COUNT(*)
FROM lectorHoeveel rijen bevat de tabel ‘opleidingsonderdeel’?
Deze tabel bevat 21 rijen.
Probeer nu volgende code uit en probeer aan de hand van de output te achterhalen wat ze doet:
SELECT *
FROM lector, opleidingsonderdeel
Door in de FROM component twee tabellen te vermelden (gescheiden
door een komma)
wordt elke rij van de tabel ‘lector’ gekoppeld aan elke rij van de
tweede tabel ‘opleidingsonderdeel’
. Elk van de 18 lectorrijen wordt dus gecombineerd met elk van de
21 OPO’s. Dat geeft in totaal 18 × 21 = 378 rijen in het resultaat. Je
zal de horizontale schuifbalk in het resultaatveld nodig hebben, want
deze rijen worden lang aangezien alle kolommen van beide tabellen
samen in het resultaat aanwezig zijn.
Dit product – een set waarbij elke rij uit de eerste tabel voorkomt met
elke rij uit de tweede tabel – wordt het cartesisch product
genoemd. Twee tabellen vermelden achter het woord FROM is een
impliciete join. We zullen later vragen om altijd een expliciete join te schrijven, maar voorlopig doen we het zo.
Kolommen selecteren in het cartesisch product
Je weet dat de FROM component altijd als eerste wordt uitgevoerd. Die laadt in dit geval het cartesisch product van beide tabellen in het
werkgeheugen. De SELECT komt pas later. Hiermee selecteer je bepaalde
kolommen.
Probeer deze code:
SELECT opocode, coordinator, lector_id, email
FROM lector, opleidingsonderdeel
Stel dat je nu, naast deze vier kolommen, ook nog de naam van het OPO
wil tonen, dan volstaat een simpele toevoeging van deze kolom in de SELECT …
SELECT opocode, naam, coordinator, lector_id, email
FROM lector, opleidingsonderdeel… zou je denken. Je krijgt echter een foutmelding:
ERROR: column reference "naam" is ambiguous
LINE 2: SELECT opocode, naam,coordinator,lector_id,email
Wat loopt er mis? Pas dan de SELECT aan zodat je ook de OPOnaam
te zien krijgt.
De databankserver laat weten dat de gevraagde kolom ‘naam’
dubbelzinnig (‘ambiguous’) is. Er zijn namelijk twee kolommen ‘naam’.
Die dubbelzinnigheid kan je wegnemen door de naam van de kolom te
laten voorafgaan door de naam van de tabel, m.a.w. iets in de stijl
van SELECT tabelnaam.kolomnaam. Als er geen dubbelzinnigheid is, is de kolomnaam natuurlijk
voldoende!
Dit kan dan een mogelijke oplossing zijn:
SELECT opocode, opleidingsonderdeel.naam, coordinator, lector_id, email
FROM lector, opleidingsonderdeelAlias voor tabelnamen
Je moet geregeld de kolom specifiëren door de tabelnaam ervoor te schrijven. Dat is redelijk wat typwerk. Een kortere optie is het gebruik van een alias (ook wel ‘pseudoniem’ genoemd). Je vervangt als het ware de naam van de tabel tijdelijk door iets korter (vaak slechts één of een paar letters). Vergelijk volgende versies van dezelfde query. Eerst de lange versie:
SELECT opocode, opleidingsonderdeel.naam, coordinator, lector_id, lector.naam, email
FROM lector, opleidingsonderdeelKorter en daardoor mogelijk vlotter leesbaar is deze versie met twee aliassen:
SELECT opocode, O.naam, coordinator, lector_id, L.naam, email
FROM lector AS L, opleidingsonderdeel AS O
Je mag eventueel het woordje AS weglaten en dus kan het nog iets
korter:
SELECT opocode, O.naam, coordinator, lector_id, L.naam, email
FROM lector L, opleidingsonderdeel O
Probeer eens de combinatie te maken waarbij je een alias definieert,
maar toch de volledige naam van de tabel gebruikt in de SELECT door volgende code uit te testen:
SELECT opocode, opleidingsonderdeel.naam, coordinator, lector_id, L.naam, email
FROM lector L, opleidingsonderdeel OWat besluit je?
De foutmelding helpt je verder:
ERROR: invalid reference to FROM-clause entry for table "opleidingsonderdeel"
LINE 2: SELECT opocode, opleidingsonderdeel.naam, coordinator, lecto...
^
HINT: Perhaps you meant to reference the table alias "o".
SQL state: 42P01
Character: 50Dit betekent dus concreet dat eens je een alias gedefinieerd hebt voor een tabelnaam, je verplicht bent om die alias te gebruiken. De tabelnaam is op dat moment tijdelijk vervangen door de alias!
Join voorwaarde
Door de impliciete join in de FROM component heb je het cartesisch product gemaakt: een combinatie van elke rij van de ene tabel met elke rij van de
tweede tabel. In totaal dus 378 combinaties van rijen. Die lange lijst moet
je nu beperken tot de ‘zinvolle’ rijen. Rijen verwijderen of behouden doe je
met een WHERE. Deze WHERE noemen we de ‘join conditie’
of ‘join voorwaarde’.
Wat zijn hier de zinvolle rijen? Elke coördinator van elk OPO wordt gekoppeld aan gelijk welke lector. We waren echter alleen op zoek naar het mailadres van de coördinator. De enige zinvolle rijen zijn dan die waar de coördinator in de OPOtabel gelijk is aan het lector_id in de lectortabel:
SELECT opocode, email
FROM lector, opleidingsonderdeel
WHERE coordinator = lector_id -- join conditieVan de 378 rijen in het cartesisch product zijn er maar 21 die aan deze voorwaarde voldoen. Dat is ook logisch: er zijn 21 OPO’s en elk OPO heeft juist één coördinator. De figuur bij het begin van dit hoofdstuk toont het resultaat in pgAdmin.
In deze oefening komen heel wat dingen uit vorige hoofdstukken aan bod. Schrijf de query die voor elk OPO van minder dan 6 studiepunten het volgende geeft: de naam van het OPO, het aantal studiepunten, voornaam en familienaam van de coördinator in één kolom en het jaar waarin dat OPO voor het eerst op het programma van de opleiding stond. Sorteer volgens stijgend aantal studiepunten. Bij gelijk aantal studiepunten moet je verder sorteren volgens jaartal (nieuwste eerst). Je moet de volgende figuur bekomen met een tabel van 13 rijen.
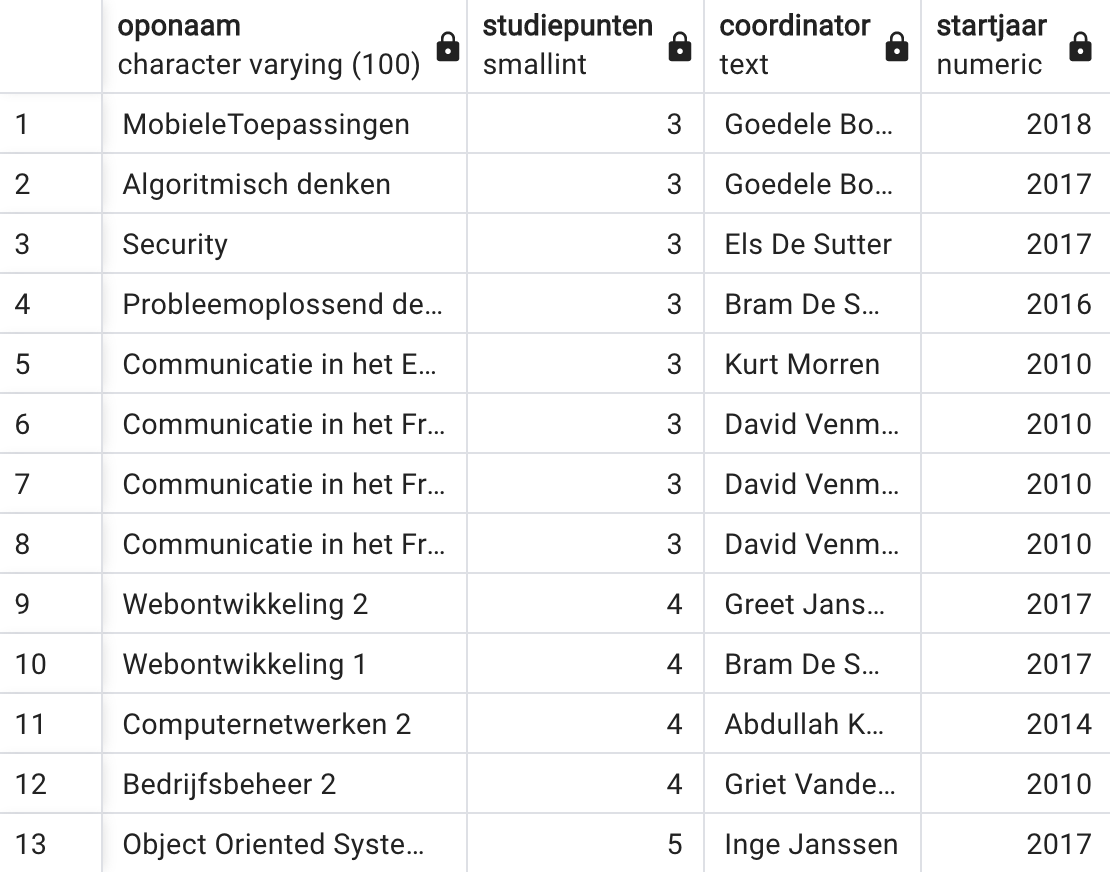
SELECT O.naam AS OPOnaam, studiepunten, L.voornaam || ' ' || L.naam AS coordinator,
EXTRACT(YEAR FROM O.van) as startjaar
FROM lector L, opleidingsonderdeel O
WHERE coordinator = lector_id AND studiepunten < 6
ORDER BY 2 ASC, 4 DESCExpliciete JOIN
De vorige oefening legt een zwakheid van de impliciete join (meerdere
tabellen in de FROM gescheiden door een komma) bloot. Zowel de join conditie
(coordinator = lector_id) als de ‘gewone’ conditie (studiepunten < 6) staan in de WHERE component. Er bestaat een alternatieve notatie
voor de
JOIN waarbij je deze bewerking expliciet zo benoemt.
De oplossing van de vorige oefening ziet er dan zo uit met een expliciete JOIN:
SELECT O.naam AS OPOnaam, studiepunten, L.voornaam || ' ' || L.naam AS coordinator,
EXTRACT(YEAR FROM O.van) as startjaar
FROM lector L INNER JOIN opleidingsonderdeel O ON coordinator = lector_id -- leesbaarder!
WHERE studiepunten < 6
ORDER BY 2 ASC, 4 DESC
De join conditie staat nu in de FROM en we vermelden expliciet
het woord JOIN. Deze notatie is logischer en je maakt minder
kans om de join conditie te vergeten of iets fout te doen in de WHERE, want deze component is nu eenvoudiger.
De volgorde waarin je de tabellen schrijft is niet belangrijk. Het woord INNER mag je ook weglaten. We raden aan om het toch altijd te schrijven. Er bestaat namelijk ook een OUTER JOIN.
Er bestaat ook een alternatieve notatie voor de join conditie die je kan gebruiken als beide kolommen in die conditie identiek dezelfde naam hebben en als je test op gelijkheid van beiden. Dat is in dit voorbeeld niet het geval, maar stel dat de kolom ‘coordinator’ ook ‘lector_id’ als naam had, dan hadden we bovenstaande code zo geschreven:
SELECT O.naam AS OPOnaam, studiepunten, L.voornaam || ' ' || L.naam AS coordinator,
EXTRACT(YEAR FROM O.van) as startjaar
FROM lector L INNER JOIN opleidingsonderdeel O ON O.lector_id = L.lector_id. -- alias nodig!
WHERE studiepunten < 6
ORDER BY 2 ASC, 4 DESC
Dit kan korter door het gebruik van USING:
SELECT O.naam AS OPOnaam, studiepunten, L.voornaam || ' ' || L.naam AS coordinator,
EXTRACT(YEAR FROM O.van) as startjaar
FROM lector L INNER JOIN opleidingsonderdeel O USING(lector_id)
WHERE studiepunten < 6
ORDER BY 2 ASC, 4 DESC
We komen hierop later terug bij de oefeningen. De notatie met ON is altijd bruikbaar, die met USING alleen in bepaalde gevallen.
Een tabel joinen met zichzelf
In een JOIN operatie combineer je twee (of meer) tabellen. Je
mag ook twee keer dezelfde tabel gebruiken. Het gebruik van aliassen
is in dit geval verplicht. Probeer volgende oefening te maken m.b.v. de tips.
Voor een wedstrijd vormen lectoren een team van twee personen. Eén persoon is de kapitein van het team, de andere is dan gewoon teamlid. Schrijf de query die een lijst genereert van alle mogelijke teams zoals getoond in bijhorende figuur. Deze lijst bevat 306 rijen. Enkele tips:
-
Het eerste teamlid zit in de tabel ‘lector’, het tweede teamlid ook.
Je doet dus een
INNER JOINvan de tabel ‘lector’ met zichzelf. - Je zal moeten onderscheid maken tussen de eerste tabel ‘lector’ en de tweede tabel ‘lector’. Gebruik als aliassen bvb. ‘L1’ en ‘L2’.
- Wat wordt de join conditie? Je kan geen team met jezelf vormen …
- Let op de kolomhoofdingen in de figuur.
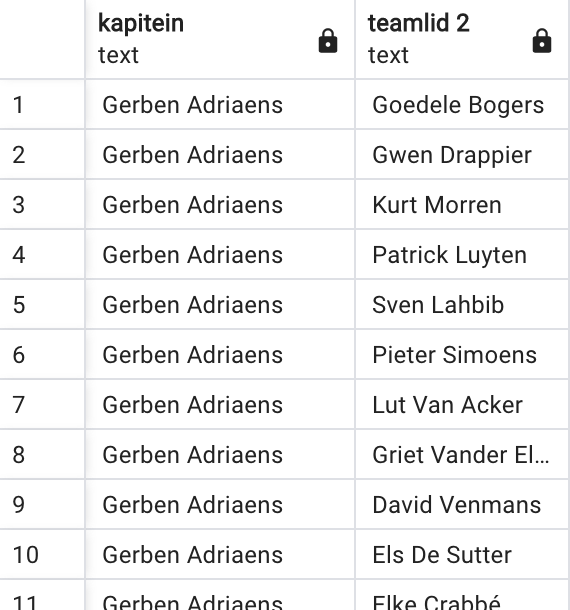
SELECT L1.voornaam || ' ' || L1.naam AS kapitein,
L2.voornaam || ' ' || L2.naam AS "teamlid 2"
FROM lector L1 INNER JOIN lector L2 on L1.lector_id != L2.lector_idWe breiden de vorige oefening een beetje uit:
We willen nog steeds een lijst van mogelijke teams van lectoren, maar met de extra voorwaarde dat beide teamleden in dezelfde gemeente moeten wonen. Je zal nu slechts 6 mogelijke teams kunnen maken. Toon ook de gemeente.
SELECT L1.voornaam || ' ' || L1.naam AS "kapitein",
L2.voornaam || ' ' || L2.naam AS "teamlid 2", L1.gemeente
FROM lector L1 INNER JOIN lector L2 on
L1.lector_id != L2.lector_id AND L1.gemeente = L2.gemeenteOefeningen
Welke OPO’s die nu in het huidige programma van TI zitten hebben een coördinator die in een gemeente woont waarvan de postcode begint met ‘3’. Schrijf de SQL query die onderstaande figuur genereert. Je hoeft niet te sorteren.

SELECT opocode, O.naam, lector_id, voornaam, L.naam, gemeente
FROM opleidingsonderdeel O INNER JOIN lector L on O.coordinator = L.lector_id
WHERE gemeente LIKE '3%' AND O.tot IS NULL
Schrijf de SQL query die de lijst genereert (zie figuur) van alle
lectoren die jonger zijn dan Gerben Adriaens. Deze lijst is gesorteerd
zodat de jongste lector bovenaan staat. Je mag veronderstellen dat er
maar één Gerben Adriaens is. Je mag niet eerst met een aparte query de geboortedatum van Gerben
Adriaens opvragen. Subquery’s zijn ook niet toegelaten, want die hebben we nog niet
gezien. Het kan met één query door een JOIN te gebruiken.
Let ook op de kolomhoofding (zoals altijd).
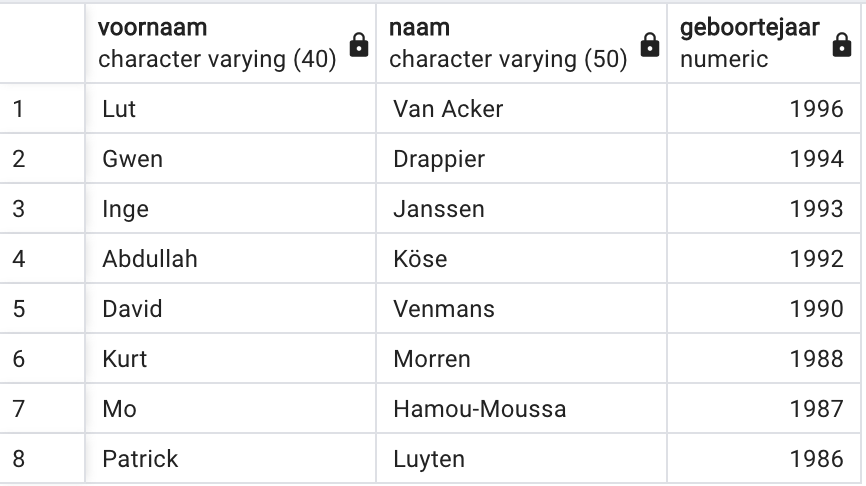
Je kan de tabel ‘lector’ opnieuw met zichzelf joinen. Let op de
speciale voorwaarde in de join conditie. Als je beter wilt zien wat er
gebeurt kan je best een SELECT * vragen zodat je de volledige rij ziet. In de WHERE wordt getest op wie jonger is. Je
bent jonger als je geboortedatum groter is.
SELECT L1.voornaam, L1.naam, EXTRACT(YEAR FROM L1.geboortedatum) AS geboortejaar
FROM lector L1 INNER JOIN lector Adr ON Adr.naam = 'Adriaens' AND Adr.voornaam = 'Gerben'
WHERE L1.geboortedatum > Adr.geboortedatum
ORDER BY 3 DESCEen student heeft nog 8 SP te kort om te kunnen afstuderen. Genereer een lijst (zie onderstaande figuur) met alle mogelijke combinaties van 2 OPO’s uit het oude programma (OPO’s die nu niet meer gegeven worden) die samen 8 studiepunten vertegenwoordigen. De kans is groot dat je een lijst bekomt waar elke combinatie twee keer in staat (als A en B samen 8 SP zijn, dan is B en A ook 8 SP en dan zijn er twee rijen met dezelfde twee OPO’s in een andere volgorde). Vind je een trucje om deze dubbels te vermijden? Sorteren hoeft niet.
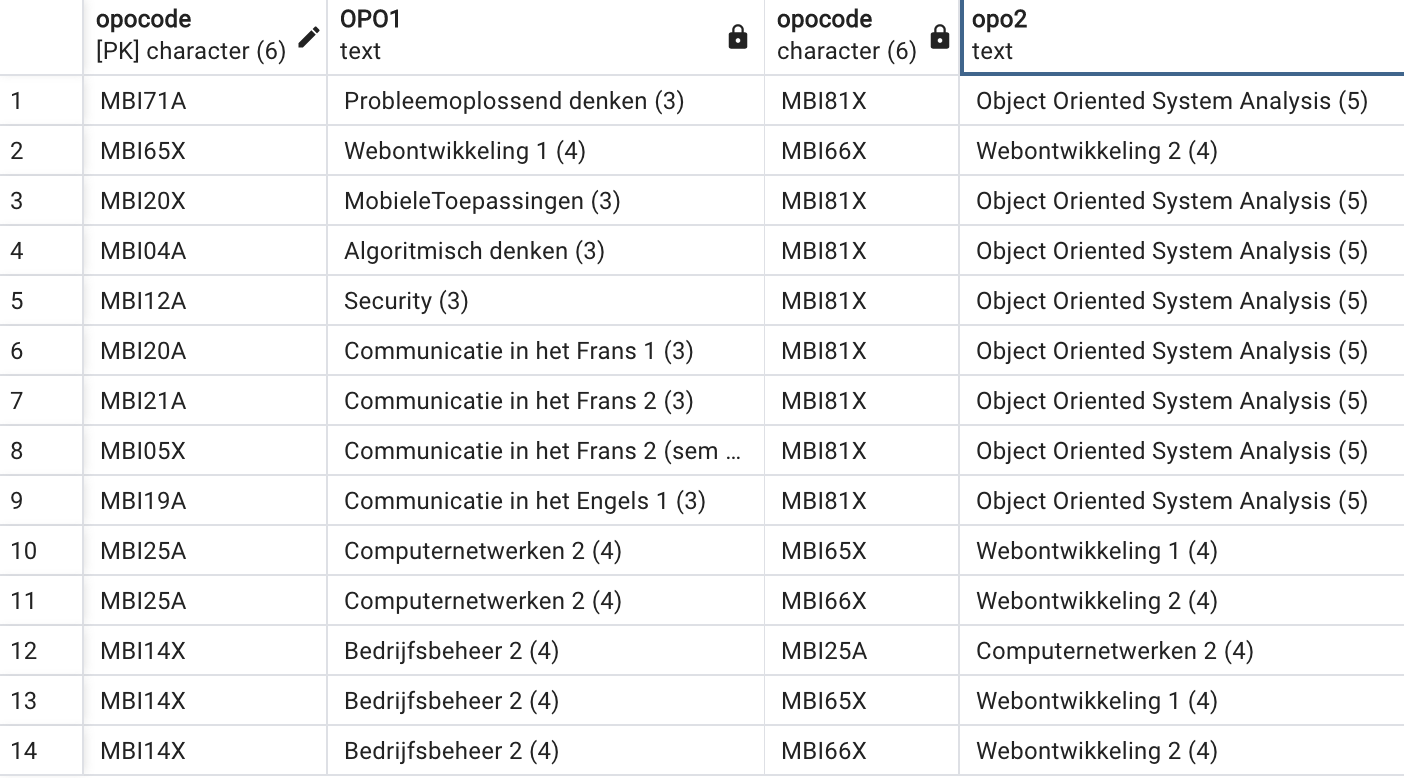
SELECT O1.opocode, O1.naam || ' (' || O1.studiepunten ||')' AS OPO1,
O2.opocode, O2.naam || ' (' || O2.studiepunten ||')' AS OPO2
FROM opleidingsonderdeel O1 INNER JOIN opleidingsonderdeel O2 on O1.opocode != O2.opocode
WHERE O1.studiepunten + O2.studiepunten = 8 AND
O1.tot IS NOT NULL AND
O2.tot IS NOT NULL AND
O1.opocode < O2.opocode -- een van mogelijke trucs om geen dubbels te hebbenOefeningen SQLzoo
Schema ‘Euro2012’
Een interessante oefenreeks op SQLzoo maakt gebruik van data i.v.m. het het Europees voetbalkampioenschap in 2012. Het logisch model op de site van SQLzoo dat bij deze oefening hoort, heeft een wat afwijkende notatie. Daarom maakten we het opnieuw volgens onze conventies:

Een woordje uitleg over dit model:
- Het schema bevat drie tabellen: ‘game’ (bevat informatie over elke wedstrijd, zoals tijdstip, stadion en tussen welke ploegen), ‘eteam’ (naam en coach van elk team) en tenslotte een tabel ‘goal’ (wie scoorde in welke minuut voor welke team een goal).
- Merk op dat de primaire sleutel van de tabel ‘goal’ een samengestelde sleutel is (twee keer PK in de tabel): er kunnen per match immers meerdere goals gescoord worden en dus zou alleen matchid onvoldoende zijn om een goal uniek te specifiëren. De combinatie van matchid en gtime (minuut waarin de goal gescoord werd) is uniek (als je veronderstelt dat er niet twee keer in dezelfde minuut gescoord kan worden 😀).
- De tabel ‘game’ heeft twee vreemde sleutels, genummerd FK1 en FK2. Een wedstrijd wordt immers tussen twee teams gespeeld en elk veld (‘team1’ en ‘team2’) verwijst dus naar een bepaald team waarover je meer informatie kan vinden in de tabel ‘eteam’).
- Je moet bovendien in dit logisch schema de kardinaliteiten goed kunnen lezen. De grote groene ellips vertelt je –als je kijkt vanuit ‘eteam’ naar ‘game’– dat elk team minstens één wedstrijd speelt. De kleinere oranje ellips duidt aan dat een wedstrijd gespeeld wordt door één uniek team1 en één uniek team2.
- Wat de kardinaliteiten van de relatie tussen de tabellen ‘goal’ en ‘eteam’ betreft: Een team kan 0 of meerdere goals maken in het toernooi (rode cirkel) en een specifieke goal hoort altijd juist bij één team (blauwe ruit).
Oefeningen op INNER JOIN
Opmerking bij deze oefeningenreeks: op de site van SQLzoo gebruikt men
telkens JOIN zonder het woordje INNER. Wij
verkiezen de volledige benaming, dus schrijf liefst altijd INNER JOIN.
Maak oefenreeks 6 op JOIN. Kleine opmerking: oefening 13 van deze oefenreeks is niet oplosbaar
met een INNER JOIN, maar wel met een OUTER JOIN. Je kan deze oefening overslaan.