Data is a precious thing and will last longer than the systems themselves.
— Tim Berners-Lee, inventor of the World Wide Web
Data en informatie
In dit hoofdstuk willen we stilstaan bij de concepten ‘data’ en ‘informatie’. Wat betekenen deze concepten exact? Waarom zijn deze begrippen belangrijk voor jou als (toekomstige) ontwikkelaar? Uit dit hoofdstuk moet je het volgende onthouden:
- wat is de betekenis van ‘data’?
- wat is de betekenis van ‘informatie’?
- wat is de rol van ‘data’ en ‘informatie’ binnen IT-toepassingen?
- waarom is er een nood aan ‘persistente data’?
- hoe draagt een DBMS bij tot het efficiënt bouwen en onderhouden van databanken?
Verschil tussen data en informatie
Voordat we je aan de slag laten gaan in deze praktisch georiënteerde cursus, willen we even stilstaan bij een aantal belangrijke begrippen. In eerste instantie willen we het hebben over data, en het onderscheid met informatie. Beide termen worden vaak door elkaar gebruikt, maar er is wel degelijk een verschil.
Data verwijst naar specifieke feiten die de vorm kunnen aannemen van cijfers, getallen, woorden, karakters, … Bijvoorbeeld ‘23’, ‘Turing’, ‘1912’, ‘Londen’, ‘Alan’ en ‘juni’ zijn elk op zich feiten die als data beschouwd kunnen worden.
Informatie verwijst naar de betekenis die gebruikers aan deze feiten gaan toekennen en de verbanden die gelegd worden tussen deze feiten. Bijvoorbeeld, aan bovenstaande feiten kunnen we de volgende informatie toekennen: ‘Op 23 juni 1912 werd Alan Turing in Londen geboren’. We combineren de data om er context en waarde aan toe te kennen.
We zijn gewend om dagelijks met data en informatie te werken, bijvoorbeeld bij het invullen van formulieren. Hoe vaak vul je niet papieren en digitale formulieren in? In de meeste van deze formulieren worden we niet om ons levensverhaal gevraagd. We moeten gerichte feiten (data) invullen, bijvoorbeeld naam, voornaam, geboortedatum, … Deze feiten worden in de structuur van een formulier gegoten. Dit formulier is vaak ontworpen in functie van een proces waarin de data verzameld, bijgehouden en verwerkt worden. Eens verwerkt kunnen de data binnen andere processen terug opgevraagd en gebruikt worden.
Laten we als voorbeeld het proces van het inschrijven aan de UCLL nemen. Bij jouw inschrijving beantwoord je een aantal vragen. Deze vragen hebben als doel om informatie te verzamelen om jouw inschrijving officieel te registreren. Je wordt bijvoorbeeld gevraagd om wat meer te vertellen over jezelf (naam, geboortedatum, …). Je duidt je eerdere opleiding (richting, school, diploma, …) aan en voor welke opleiding je je zou willen inschrijven (opleiding, afstudeertraject, …). De informatie die je geeft, wordt in stukken gekapt tot atomaire deeltjes, de data. Elk stukje data wordt in een veld van het formulier ingevuld. Van zodra het formulier wordt verzonden, worden de data ook als atomaire deeltjes opgeslagen.
De data zijn nu opgeslagen volgens de structuur van het inschrijvingsformulier. De medewerkers van de administratie gebruiken de gegevens van de inschrijvingen om het academiejaar voor te bereiden. De data laat hen toe om klassen samen te stellen, uurroosters te maken, … Met andere woorden, de data die eerder bij de inschrijving werden verzameld, worden nu terug tot informatie gepuzzeld om andere processen mogelijk te maken. In de vertaalslag van verzamelde data naar nuttige informatie, wordt de data vaak volgens een andere logica gestructureerd. Bijvoorbeeld, de samenstelling van de klassen houdt geen rekening met de geboortedatum, maar wel met het aantal studenten die voor een opleiding en afstudeertraject zijn ingeschreven. Daarnaast kan de data ook gecombineerd worden met andere data. Bijvoorbeeld: het opstellen van de uurroosters gebeurt op basis van inschrijvingen, maar ook op basis van de beschikbaarheid van docenten en lokalen.
En hier ligt de rol van jullie als toekomstige ontwikkelaars. Het is jullie rol om na te denken over het belang van informatie voor jullie toepassingen, de vertaling van informatie naar gestructureerde data en hoe deze data op een efficiënte manier kunnen opgeslagen worden. Het is aan jullie om de logica te bepalen om vanuit gestructureerde data informatie te maken en omgekeerd.
Data en IT toepassingen
Zoals hierboven vermeld, worden data vaak verzameld in functie van een proces. IT-toepassingen worden vaak ontwikkeld met het oog op het digitaliseren of automatiseren van manuele processen. Het eerdere voorbeeld beschreef het online inschrijven van een student voor een opleiding aan de UCLL. Vroeger gebeurde dit volledig op papier, inclusief het manuele werk om de inschrijvingen te verwerken, wat ineens ook resulteerde in een groter risico op fouten. Ondertussen is dit proces gedigitaliseerd en geautomatiseerd als een IT-toepassing.
Doorgaans zal dus een IT-toepassing in staat zijn om data te verzamelen, te verwerken en op te slaan. In de andere richting moeten ze dus ook in staat zijn om opgeslagen data op te vragen en te tonen aan de gebruikers. Er is bijgevolg nood om data voor een langere periode op te slaan. Het opslaan van data voor een langere periode noemen we persistente gegevensopslag of anders gezegd ‘het persistent opslaan van data’.
Bij het ontwerpen van een IT-toepassing zal het team van ontwikkelaars hiervoor een architectuur bepalen. Hierbij wordt nagedacht welke componenten noodzakelijk zijn om een goede IT-toepassing te bouwen. Een applicatie wordt dus niet beschouwd als een monolithisch geheel, maar als een samenstelling van verschillende componenten die elk een bepaalde functie hebben. Deze componenten zijn bijvoorbeeld een interface voor mobiele toestellen (front-end), de mogelijkheid om met andere applicaties te communiceren, … De verschillende componenten vervullen elk een bepaalde functie (dit komt later in je opleiding uitgebreid aan bod). In heel wat gevallen zal een vorm van persistente gegevensopslag onderdeel van de architectuur vormen. In de afgelopen decennia is er heel wat technologie ontwikkeld die persistente gegevensopslag mogelijk maakt. In het kader van dit vak richten we ons op relationele databanken en DBMS aangezien dit de meest gebruikte technologie is voor persistente gegevensopslag, maar zeker niet de enige.
Databanken en DBMS
Als ontwikkelaar zal je in het kader van je IT-toepassingen dus data verzamelen, verwerken en tonen aan gebruikers. Alle data die je verzamelt, kan in een databank verzameld worden. Een databank wordt gezien als een verzameling van opgeslagen data of correcter ‘persistente data’. Bijvoorbeeld, het systeem van de studentenadministratie van de UCLL omvat de data betreffende studenten, inschrijvingen, opleidingsonderdelen, … die samen in een databank vervat zitten.
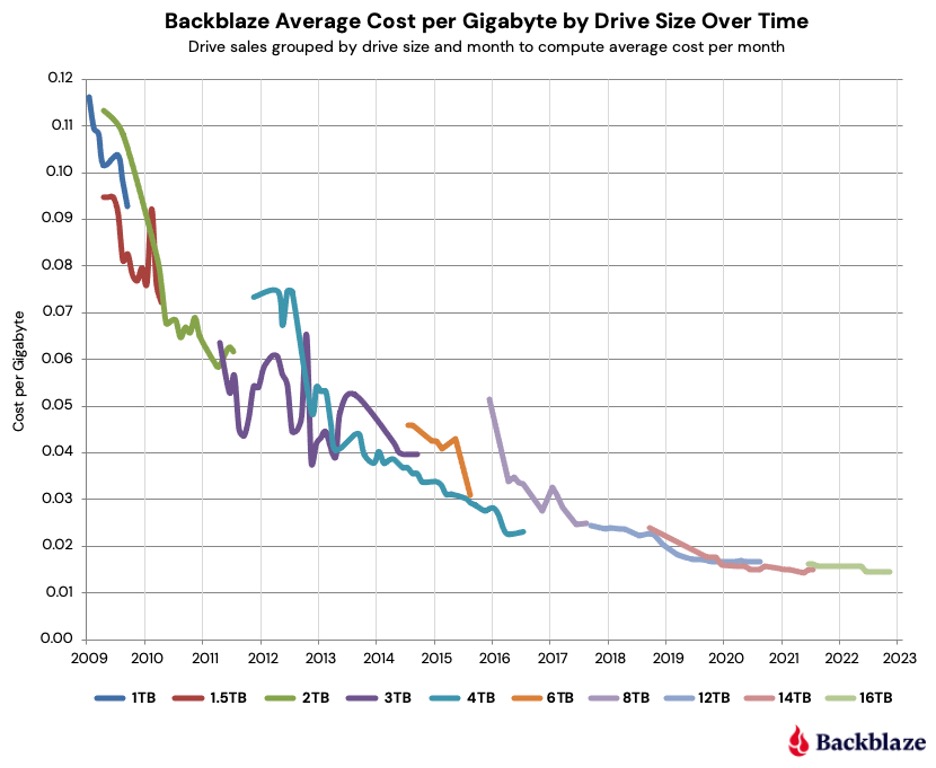
Tegenwoordig wordt persistente data opgeslagen in het permanente geheugen van een computersysteem. Het permanente geheugen of opslagmedium kan verschillende vormen aannemen, bijvoorbeeld harde schijven, magneetbanden, CD-ROM, … De opslag van data komt met een bepaalde kost die sterk afhangt van het gebruikte opslagmedium. Vandaar is het zeer belangrijk voor een team van ontwikkelaars om stil te staan bij de waarde van data die aan een databank wordt toegevoegd en een afweging te maken tussen welke data in de databank wordt opgenomen en welke niet. Dat gezegd zijnde, de kost van dataopslag is sinds de jaren 2000 zeer sterk gedaald, dus wat extra data bijhouden zal in heel wat gevallen geen problemen opleveren. Ter illustratie een afbeelding van de dalende "kostprijs per gigabyte" voor harde schijven. (bron figuur).
De technologie die we gebruiken om databanken op te bouwen, te onderhouden, te beheren, te beveiligen en te bevragen (data uit de databank halen) noemen we een database management systeem (DBMS) . Het DBMS is dus een softwarepakket dat dienst doet als een interface tussen enerzijds de eindgebruikers en anderzijds de databank.
Er bestaan heel wat database management systemen en in het kader van dit vak maken we gebruik van PostgreSQL. Andere voorbeelden hiervan zijn MySQL, Oracle, Microsoft SQL Server, IBM DB2, MongoDB, Neo4j, …

Database management systemen bestaan in heel wat verschillende vormen, waarvan bepaalde systemen zijn ontwikkeld voor specifieke toepassingen. Bij de keuze van een database management systeem wordt naar heel wat verschillende factoren gekeken, gaande van kostprijs van een licentie, de manier waarop de data wordt gestructureerd, data beveiliging, features, … maar dit valt buiten het doel van dit vak.
Waarom kiezen we voor postgreSQL?
PostgreSQL is een open-source database management systeem. Het biedt robuuste functies voor gegevensopslag, beveiliging en beheer, en wordt vaak gebruikt vanwege zijn betrouwbaarheid en flexibiliteit. PostgreSQL ondersteunt geavanceerde gegevensmodellen en query-optimalisatie, waardoor het een populaire keuze is voor zowel kleine als grote toepassingen.
Er is bovendien een actieve community rond postgreSQL die regelmatig updates, bugfixes en nieuwe features brengt. Je kan het gratis lokaal installeren (op je eigen computer). Er zijn versies voor Linux, Windows en macOS.
Voor de dagopleiding Toegepaste Informatica is het belangrijk dat studenten met vele honderden tegelijk in teams van 4 à 5 studenten kunnen werken op de server. In het afstandstraject, waar je individueel aan opdrachten werkt, speelt dit argument natuurlijk niet.