The great thing about a database is that you can ask it a question that you hadn't thought of before and get an answer.
— Michael Stonebraker
Van vraag naar data
In dit hoofdstuk willen we even stilstaan bij hoe datasets en databanken tot stand komen. Je moet uit dit hoofdstuk het volgende onthouden:
- datamodelleren als een stap in de analyse van IT toepassingen;
- een stapsgewijze aanpak voor de ontwikkeling van een databank;
- conceptueel, logisch en fysiek datamodel.
Start met een vraag
In het inleidend hoofdstukje SQL hebben we al kort toegelicht hoe we, gebruik makende van SQL, een bestaande dataset kunnen bevragen. In de volgende hoofdstukken gaan jullie hier nog verder in op de mogelijkheden die SQL te bieden heeft. Parallel willen we een andere uitdaging toelichten, namelijk het bouwen van datasets en databanken. We gaan in op volgende vragen:
- hoe komen datasets en databanken tot stand?
- welk proces leidt tot een goed opgebouwde databank?
- wat bepaalt of een databank goed gebouwd is?
Vooraleer we bekijken hoe datasets en databanken tot stand komen, bekijken we een vergelijkbaar proces, namelijk het bouwen van een huis. Stel dat je een huis zou willen laten bouwen, hoe ga je dan te werk? In eerste instantie start je met een vraag of nood om iets te bouwen. Je wilt bijvoorbeeld een huis voor jouw gezin bouwen. Van zodra je weet dat je een huis gaat bouwen, neem je contact op met een architect. De architect gaat samen met jou nadenken van wat er exact gebouwd moet worden, door heel wat vragen te stellen om goed te begrijpen hoe jouw huis eruit moet zien.
Ondertussen gaat de architect, gebruik makende van zijn technische expertise, erover waken dat tijdens het ontwerpen van het huis een aantal basisprincipes en goede praktijken gerespecteerd worden. Na jullie overleg tekent de architect een grondplan.
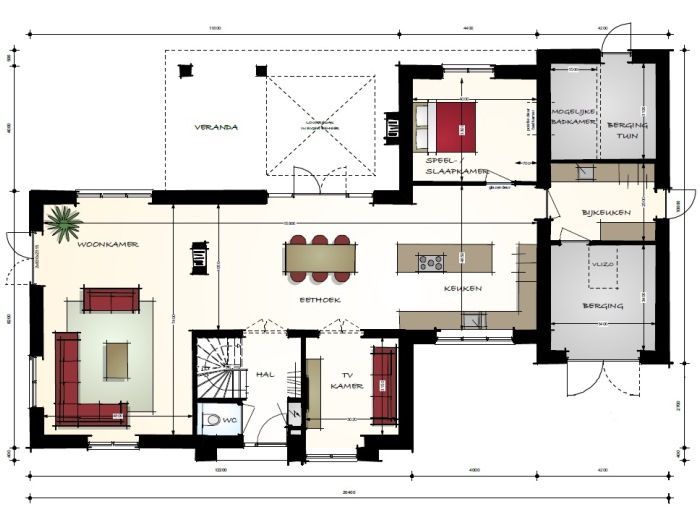
Dit grondplan wordt samen met jou besproken om zeker te zijn dat de interpretatie van de architect overeenkomt met jouw verwachtingen. In latere fases zal de architect van dit plan meer gedetailleerde versies maken zodat aannemers, elektriciens, loodgieters, … weten hoe jouw huis gemaakt moet worden. Dit gedetailleerde grondplan wordt goed bewaard zodat er een overzicht is waar bepaalde constructie-elementen (waterleidingen, elektriciteit, steunbalken, …) zich bevinden.
Vraag naar data
Voor de bouw van een databank loopt het proces gelijkaardig. Een databank start typisch met een vraag om data bij te houden, bijvoorbeeld data die binnen software verzameld wordt. Een architect (die hebben we ook in IT) of een analist zal samen met gebruikers en ontwikkelaars nadenken welke data er in een databank terecht moet komen. Op basis van die gesprekken wordt er door de analist een datamodel uitgetekend dat besproken wordt met de relevante partijen.
Dit model wordt dan in een aantal stappen verder in detail uitgewerkt tot een bouwplan voor een databank. Dit bouwplan laat de ontwikkelaars van de databank toe om de databank te bouwen. Het laat de ontwikkelaars van de software ook toe om van start te gaan met de ontwikkeling van de toepassing. Want van zodra er afspraken zijn over de structuur van de databank, kan je als ontwikkelaar jouw code schrijven die met deze structuur aan de slag gaat, zonder dat de databank gebouwd is. Later wanneer de databank gebouwd is, kan de code getest worden. Tenslotte vormen de modellen een belangrijke bron voor documentatie voor analisten en ontwikkelaars voor de verdere ontwikkeling en onderhoud van de systemen.
Analyse
De ontwikkeling van een IT oplossing loopt (idealiter) volgens een stappenplan. Er bestaan heel wat verschillende gestandaardiseerde varianten van zo'n stappenplan, wat we later in de opleiding ontwikkelingsmethodologieën zullen noemen. Een ontwikkelingsmethodologie kan lineair of iteratief zijn, en bestaat uit een aantal fases.
Een belangrijke fase die in zowat elke ontwikkelingsmethodologie voor IT toepassingen terugkomt, is de analyse-fase of kortweg analyse. Binnen de analyse-fase gaan we de vraag naar een IT toepassing vertalen naar een aantal functionele en technische vereisten. Het resultaat van deze fase noemen we de (behoefte-)analyse.
De analyse is een essentiële fase waarin we het probleem, het te automatiseren proces, de achterliggende logica, ... goed proberen te begrijpen voor we starten met de implementatie. We gaan in deze fase documentatie doornemen, interviews afnemen, workshops organiseren, ... om zelf informatie te verzamelen. Vervolgens gaan we die informatie op een bepaalde manier structureren. Er bestaan heel wat verschillende methodes die binnen een analyse gebruikt worden, waarvan je er sowieso enkele binnen dit OPO en in de verdere opleiding zal ontdekken.
Het deelproces van de analyse waarbij we de vereisten voor informatie en bijgevolg data in kaart brengen, noemen we datamodelleren. Als onderdeel voor de vraag naar software, gaan we evalueren welke vraag er bestaat om data persistent bij te houden.
In latere vakken wordt dieper ingegaan op het concept ontwikkelmethodologie. Jullie gaan verschillende varianten (o.a. agile, DevOps, waterval, rapid application development) meer in de diepte bestuderen.
Datamodelleren
Datamodelleren verloopt in een aantal stappen. In elke stap proberen we een bepaalde vraag te beantwoorden (de specifieke vragen komen hieronder aan bod). Het resultaat van elke stap resulteert in een datamodel, waarbij we al dan niet verder bouwen op een datamodel van een eerdere stap. Elke stap resulteert in een datamodel en bijbehorende documentatie.
Een datamodel is een visuele en schematische voorstelling van de data die we in een databank willen opnemen. Het bevat de verschillende stukjes data die samen de databank vormen en de verbanden die er tussen deze stukjes bestaan. Om het datamodel uit te tekenen, maken we gebruik van een gestandaardiseerde notatie.
Er zijn bepaalde voordelen aan het gebruik van een gestandaardiseerde notatie. In eerste instantie bevordert het de leesbaarheid van het datamodel. Als er duidelijke afspraken zijn welke symbolen gebruikt worden en hoe je ze moet interpreteren, kan iedereen die de notatie kent het datamodel lezen en interpreteren. De datamodellen kunnen zo makkelijk uitgewisseld worden.
Een tweede voordeel is dat de notatie ontwikkeld is om complexe concepten op een eenvoudige manier voor te kunnen stellen. Het vereenvoudigt en versnelt het ontwerpen van een datamodel. Neem hier nog bij dat er heel wat tools zijn die toelaten om deze datamodellen digitaal te maken, en je kan snel en efficiënt te werk gaan.
Aangezien datamodelleren van een databank in stappen verloopt, en elke stap resulteert in een datamodel, zullen we voor een databank meerdere datamodellen hebben. We spreken hier over lagen waarbij elk datamodel een bepaalde laag vormt en zoals eerder gezegd een bepaalde vraag beantwoordt.
In ons proces onderscheiden we drie types (lagen) van datamodellen: conceptueel, logisch en fysiek.

Conceptueel datamodel
De eerste stap is het uittekenen van een conceptueel datamodel waarbij we een antwoord definiëren op de vraag “Welke informatie is relevant voor de beoogde IT toepassing?”. In dit datamodel creëren we een beeld op de realiteit van de gebruikers zonder hierbij technische details of technische beperkingen mee in rekening te nemen. De focus ligt daarentegen op de relevante concepten en bedrijfslogica (‘business logic’).
Het conceptueel datamodel laat ook toe het bereik (‘scope’) van het datamodel goed af te bakenen, zodat alle betrokkenen duidelijk zicht hebben op wat van belang is. Het geeft een beeld op wat er meegenomen wordt in de toepassing, en wat er niet meegenomen wordt.
Bij het uittekenen van het conceptueel model proberen we de volgende vragen te beantwoorden:
- welke concepten zijn belangrijk voor onze applicatie?
- hoe gaan we die concepten beschrijven?
- welke verbanden liggen er tussen deze concepten?
Het conceptueel datamodel komt typisch tot stand als een samenwerking tussen analisten en gebruikers. De gebruikers beschrijven tijdens workshops, interviews, … welke informatie relevant is.
De analist verzamelt deze informatie en bundelt deze in een conceptueel datamodel. Dit datamodel dient als een communicatiemiddel tussen de verschillende betrokken partijen. Door het eenvoudige karakter van het conceptueel datamodel kunnen gebruikers makkelijk evalueren of de interpretatie van de analisten correct is. Anderzijds bevat het voldoende informatie voor de analisten om hier verder mee aan de slag te gaan.
Heel belangrijk: op dit niveau wordt er nog niet gesproken over technologie, enkel high-level welke informatie relevant is voor de gebruikers. Dat maakt het conceptueel datamodel ook zo waardevol: na deze stap kan het ontwikkelteam van de toepassing nog alle richtingen uit.
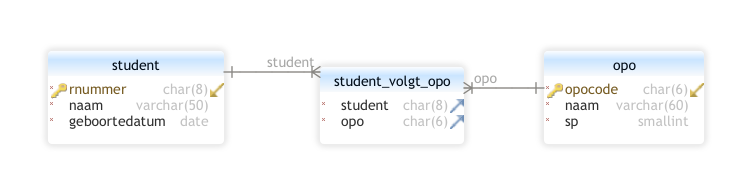
Onderstaand conceptueel datamodel vertelt volgend verhaal: “Een student (met een aantal gegevens zoals r-nummer enz.) volgt minstens één OPO, terwijl dit OPO (code, aantal studiepunten SP enz.) door meerdere studenten kan gevolgd worden. Eventueel is het ook mogelijk dat er een OPO is dat door geen enkele student gekozen wordt.”. Deze tekening kan ook door niet-technische mensen gelezen worden en kan zo als basis dienen voor een gesprek.

We gaan later dieper in op het conceptueel datamodel en hoe dit tot stand komt.
Logisch datamodel
Van zodra we zicht hebben op de informatie en bijgevolg de concrete data, feiten of gegevens die voor de gebruikers relevant zijn, proberen we de volgende vraag te beantwoorden: “Welk databankmodel is het meest geschikt voor de ontwikkeling van onze databank?”. Er bestaan namelijk verschillende databankmodellen (niet te verwarren met datamodellen) waarbij elk van de databankmodellen een manier definieert om data te structureren. Elk databankmodel heeft zijn voor- en nadelen of specifieke toepassingen, en een goede overweging is noodzakelijk.
De keuze voor een bepaald databankmodel wordt typisch gemaakt in samenspraak tussen de analisten (met zicht op de data die gemodelleerd wordt), de architect (met zicht op de brede technische omgeving waarin de toepassing wordt ontwikkeld) en de ontwikkelaars (met zicht op de technologie die voor de toepassing gebruikt zal worden). De impact van de keuze is niet alleen relevant voor de databank, maar legt ook beperkingen op voor het DBMS en de technologie die gebruikt worden.
Na de keuze voor een bepaald databankmodel vertaalt de analist het conceptuele datamodel naar een logisch datamodel rekening houdend met de specifieke regels van het databankmodel. Sommige databankmodellen gaan bijvoorbeeld een beperking leggen op het type van relaties dat er tussen de data kan bestaan. In dit geval gaan we tijdens de omzetting de niet ondersteunde types van relaties omzetten naar relatietypes die wel ondersteund worden. Ongetwijfeld klinkt dit allemaal wat abstract, maar we komen hier later uitgebreid op terug.
In heel wat gevallen zal gekozen worden voor een relationeel databankmodel. In het geval van deze keuze wordt het logisch datamodel dan ook een relationeel datamodel genoemd. We leggen binnen dit vak de focus op het relationeel databankmodel en komen hier in een later hoofdstuk uitgebreid op terug.
In de volgende figuur vind je de vertaling van het conceptueel model naar een logisch model. Er is gekozen voor een relationeel model. Het is al een stuk technischer (drie tabellen, primaire en vreemde sleutel, … zie later), maar laat toch nog bepaalde details weg omdat er nog niet specifiek gekozen is voor welk DBMS.

Voor relationele datamodellen zijn er ook normen gedefinieerd, we noemen deze normaalvormen. Er bestaan verschillende niveaus van normaalvormen. Elke normaalvorm bestaat uit een aantal technische criteria. Elk niveau legt bijkomende criteria op. Een datamodel dat aan de criteria van een normaalvorm voldoet, voldoet aan de normaalvorm. De criteria zijn gedefinieerd om mogelijke fouten in het gebruik van de databank te voorkomen. Door aan te geven dat een datamodel een bepaalde normaalvorm volgt, geef je dus een garantie dat bepaalde regels binnen het datamodel gerespecteerd worden. We komen hier later op terug.
Het logisch datamodel is net omwille van de omzetting naar een specifiek databankmodel al een stukje technischer dan het conceptueel datamodel. Dit maakt de leesbaarheid van het datamodel ook wat moeilijker voor niet-IT medewerkers. Toch bevat het datamodel nog te weinig technische informatie voor de ontwikkelaars van de databank, zodat een bijkomende stap nodig is, namelijk de omzetting voor een specifiek DBMS. Dus op naar het fysiek datamodel …
Ook aan het logisch model is een volledig hoofdstuk gewijd.
Fysiek datamodel
In de laatste stap ligt de focus op de vraag “Welk DBMS gaan we gebruiken om de data op te slaan?”. In de ontwikkeling van het fysiek datamodel worden beslissingen genomen hoe de data fysiek gestructureerd zal worden binnen de databank, rekening houdend met het gekozen DBMS. Elk DBMS heeft zo zijn eigen mogelijkheden en uitdagingen waar een ontwikkelteam gebruik van kan maken of rekening mee moet houden. Daarnaast zijn er ook heel wat overwegingen die gemaakt moeten worden naar performantie, beveiliging, … Al deze technische beslissingen komen samen in het fysiek datamodel.
In deze fase gaan architecten, database administrators en ontwikkelaars evalueren welk DBMS gebruikt zal worden. In heel wat gevallen ligt deze keuze al vast aangezien de meeste organisaties in hun architectuur al een keuze hebben gemaakt. Het combineren van verschillende DBMS in dezelfde architectuur betekent bijkomende complexiteit en kosten, dus dat wordt in de meeste gevallen vermeden waar mogelijk.
Van zodra de keuze voor een DBMS vast ligt, gaan database administrators en ontwikkelaars de structuur van de databank evalueren en technische details bepalen hoe de data concreet opgeslagen zal worden. Deze analyse resulteert in het fysiek datamodel waarin al deze informatie vervat zit. Het fysiek datamodel laat de ontwikkelaars toe om de nodige structureren te implementeren en de databank op te bouwen.
De laatste figuur vertaalt het vorige (logische) relationele datamodel
naar een fysiek datamodel, specifiek voor PostgreSQL. De tekening bevat nu
ook concrete details, zoals datatypes (char(8), smallint, …). Ze is trouwens gemaakt met een andere tool, die met een specifieke
server kan communiceren (DBSchema, zie later).
We komen in een later hoofdstuk meer in detail terug op het fysiek datamodel.